근본 원인 — Google API의 구조적 한계
TTS 퀄리티 문제
Google AI Studio TTS(Gemini TTS)와 일반 Google Cloud TTS는 완전히 다른 엔진입니다.
| Google AI Studio TTS | Google Cloud TTS (Standard/WaveNet) | |
|---|---|---|
| 엔진 | Gemini 기반 | 구형 WaveNet/Neural2 |
| 감정/억양 | 자연스러움 | 로봇틱 |
| API 접근 | Opal에서는 내부 연동 | 외부 API는 구형 엔진 노출 |
Opal에서 잘 들리는 건 내부적으로 Gemini TTS를 쓰기 때문이고, 외부 API로 연동하면 구형 엔진이 나오는 겁니다.
이미지 생성 중국풍 문제
Imagen 계열 API는 레퍼런스 이미지 컨트롤이 매우 약합니다. 참조 이미지를 줘도 스타일 가이드 수준으로만 반영되고, 학습 데이터 편향 때문에 동양인 얼굴이나 특정 스타일 요청 시 중국풍으로 흐르는 건 알려진 문제예요.
영상처럼 퀄리티가 나오려면 — API 교체가 답
솔직히 말씀드리면 Google API 조합으로는 그 영상 수준이 안 나옵니다. 현재 기준으로 각 단계별 실질적인 대안은:
TTS
ElevenLabs — 현재 가장 자연스러운 한국어 TTS. API도 안정적이고 감정 조절 가능. 월 $5 플랜도 실용적입니다.
이미지 생성 (참조 이미지 반영)
GPT-image-1 (OpenAI) — 위 영상의 codex-sangpye가 내부적으로 쓰는 바로 그 엔진. 참조 이미지 반영률이 현재 API 중 가장 높습니다. Imagen과 비교 자체가 안 됩니다.
영상 합성
Kling AI API 또는 RunwayML — 이미지→영상 변환. 한국 서비스인 Kling이 가성비 좋습니다.
현실적인 재구성 방향
wmpro.4men.kr 시스템을 살리면서 퀄리티를 올리려면:
블로그 텍스트 입력
↓
Anthropic API (Claude) → 대본 + 장면 스펙 생성 ← 컨텍스트 유지가 핵심
↓
ElevenLabs API → TTS 오디오
↓
GPT-image-1 API → 장면별 이미지
↓
FFmpeg → 영상 합성 (로컬 or 서버)
↓
SNS 업로드PHP로 각 단계를 잡 큐로 관리하면 중간 실패 시 해당 단계만 재시도할 수 있어서 "전체가 꼬이는" 문제도 해결됩니다.
가장 현실적인 첫 번째 단계
지금 Opal에서 잘 되고 있다고 하셨는데, Opal의 워크플로우를 그대로 분석해서 어떤 API 조합을 내부적으로 쓰는지 파악하는 것이 가장 빠릅니다. Opal이 Gemini 기반이니까 Gemini API의 최신 엔드포인트(
gemini-2.0-flash
, Live API)는 외부에서도 접근 가능한데, TTS 부분만
gemini-2.5-pro
기반 TTS로 교체하면 퀄리티가 크게 달라질 수 있습니다.
--
결론부터 — 한글 처리, 이제는 됩니다
그것도 GPT-Image-1이 아니라 4월 21일 출시된 gpt-image-2가 현재 기준입니다.
한글 렌더링 상황
gpt-image-2는 "폴리글랏" 모델로 공식 설명되며, 일본어·한국어·중국어·힌디어·벵골어 등 비라틴 문자의 고품질 렌더링을 지원합니다. 한글(Hangul)을 교육용 레이아웃 내에서 정확하게 렌더링하는 것이 확인됐습니다. VentureBeat
작은 UI 레이블, 로고, 캡션, 비라틴 스크립트(한국어 포함)가 이제 수동 재작업 없이 바로 납품 가능한 수준으로 렌더링됩니다. Apidog
gpt-image-1 vs gpt-image-2 비교
| gpt-image-1 | gpt-image-2 | |
|---|---|---|
| 한글 렌더링 | 개선됐지만 불안정 | 실용 수준 |
| 최대 해상도 | 1536px | 2000px |
| Thinking 모드 | 없음 | 있음 (레이아웃 사전 계획) |
| 이미지당 비용 | ~$0.04 | ~$0.21 |
| API 모델 ID |
gpt-image-1
|
gpt-image-2
|
한 가지 주의할 점
ChatGPT 웹 UI에서 나오는 결과와 API에서 나오는 결과 간에 텍스트 렌더링 품질 차이가 존재한다는 보고가 있습니다. OpenAI Developer Community 즉 ChatGPT에서 직접 생성하면 더 잘 나오고, API로 뽑으면 약간 차이가 날 수 있습니다. 하지만 gpt-image-2는 이 격차도 많이 줄었다는 평가입니다.
상세페이지 파이프라인과 연결하면
codex-sangpye가 내부적으로 gpt-image-1 기반의
image_generation
툴을 쓰는데, 이걸 직접 gpt-image-2 API로 교체하면 한글 텍스트 품질이 한 단계 올라갑니다. 세모이 쇼츠 자막이 이미지에 박히는 형태라면 특히 체감 차이가 클 거예요.
비용은 이미지 한 장당 약 $0.21 수준인데, 상세페이지 13섹션 기준으로 5개 번들 생성이면 1회 실행에 약 $1~1.5 정도로 보시면 됩니다.
---
일단 내가 원하는 것은
- 주제와 참고 자료를 가지고 블로그 글쓰기, 썸네일 생성, 인포그래픽 생성
- 블로글을 가지고 인스타 업로드 이미지 생성(카드뉴스 형식), 인스타 문구, 해시태그 생성
- 5~10분 정도의 롱폼 대본 생성, 분량에 따른 키샷 이미지 생성(참조 이미지 스타일로)
- 구어체 오디오 스크립트 생성 -> 오디오 생성
- 영상생성, 같은 과정으로 1분 정도의 쇼츠 영상생성 필요시 이렇게 생성된 것을 사용자별 자신의 계정에 업로드
이것을 [wmpro.4men.kr](http://wmpro.4men.kr)을 바꾸기..
현실적인 전체 아키텍처 진단
먼저 솔직하게 단계별 난이도와 현재 기술 성숙도를 평가해드릴게요.
V
V
전체 구조를 보시면서 읽어주세요.
단계별 현실 평가
① ② — 바로 시작 가능 Claude API로 블로그 글, 카드뉴스 카피, 해시태그까지 한 번에 뽑고, gpt-image-2로 한글 텍스트 포함 이미지 생성. 이 두 단계는 지금 당장 PHP로 붙여도 안정적으로 돌아갑니다.
③ — 가능하지만 설계가 중요 롱폼 대본의 핵심은 "장면 스펙(scene spec)"을 Claude가 먼저 설계하게 하는 겁니다. 대본 → 씬 번호 → 각 씬의 이미지 프롬프트 순서로 컨텍스트를 넘겨야 키샷 이미지가 대본과 일치합니다.
④ — ElevenLabs로 교체 필수 Google TTS는 아까 확인한 대로 포기하는 게 맞고, ElevenLabs 한국어는 실용 수준입니다. Claude가 구어체 변환 + 감정 태그까지 해주면 훨씬 자연스럽게 나옵니다.
⑤ — 현실적으로 가장 어려운 단계 이미지+오디오 → FFmpeg 합성은 PHP에서도 가능합니다. 문제는 "영상 생성(움직이는 영상)"인데, Kling/Runway API는 아직 불안정하고 비용도 높습니다. 초기에는 이미지 슬라이드쇼 + 오디오 합성 방식으로 먼저 가고, 나중에 영상 생성 API를 붙이는 게 현실적입니다.
wmpro.4men.kr 재구성 전략
지금 PHP 기반이시니까 가장 큰 문제는 아까 말씀드린 잡 큐 없는 직렬 실행 구조입니다. 각 단계를 별도 잡으로 분리해서 실패 시 해당 단계만 재시도하게 만드는 게 먼저입니다.
방향 재정립
FFmpeg 서버 합성은 빼고, "AI가 재료를 만들어주면 사람이 캡컷/파이널컷으로 완성" 구조로 가는 거죠.
이게 사실 주부/초보자 타겟에 훨씬 맞습니다. 캡컷은 이미 많은 분들이 쓰고 있고, AI가 만들어준 오디오+이미지를 캡컷에 올리는 건 진입장벽이 거의 없으니까요.
실제로 만들어야 할 것
복잡하게 생각할 필요 없이, 결국 이 시스템이 해야 할 일은 딱 하나입니다.
"좋은 재료 파일들을 깔끔하게 다운받을 수 있게 해주는 것"
사용자 입력 (주제 + 참고자료)
↓
AI가 전부 생성
↓
┌─────────────────────────┐
│ 📄 블로그 본문 (텍스트) │
│ 🖼 썸네일 이미지 │
│ 🖼 인포그래픽 이미지 │
│ 🖼 카드뉴스 이미지 5장 │
│ 📝 인스타 문구 + 해시태그 │
│ 🖼 키샷 이미지 10~15장 │
│ 🎙 오디오 파일 (mp3) │
│ 📋 대본 (씬 타임코드 포함)│
└─────────────────────────┘
↓
ZIP으로 한 번에 다운로드캡컷에서 키샷 이미지 순서대로 올리고, 오디오 얹고, 자막 붙이면 끝. 대본에 씬 타임코드가 있으면 편집도 쉬워집니다.
UI 설계 원칙 (주부/초보자 기준)
지금 wmpro.4men.kr이 어떻게 생겼는지 못 봤지만, 이 타겟층에는:
복잡한 설정 화면 = 이탈 입니다.
화면이 세 개면 충분합니다.
- 입력 화면 — 주제 입력창 하나, 참고자료 붙여넣기 하나, 카테고리 선택, "생성 시작" 버튼
- 진행 화면 — "블로그 작성 중... ✓ / 이미지 생성 중... / 오디오 생성 중..." 단계별 표시
- 결과 화면 — 미리보기 + 각 파일 개별 다운로드 + ZIP 전체 다운로드
SNS 업로드 자동화는 나중에 옵션으로 붙이는 게 맞습니다. 초기에는 "다운받아서 직접 올리기"로도 충분히 가치 있어요.
---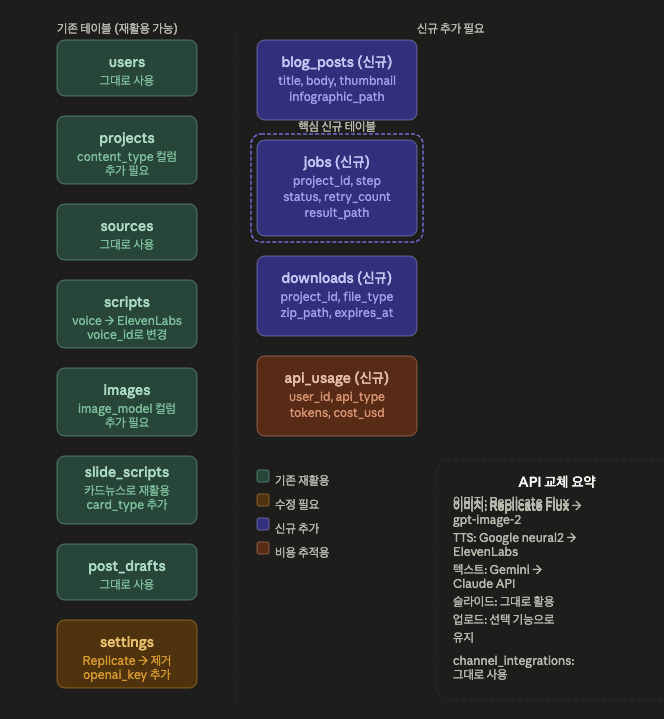
현재 DB의 강점
sources
→
scripts
→
images
→
post_drafts
→
posts
흐름이 이미 정확하게 잡혀 있습니다.
slide_scripts
도 카드뉴스로 그대로 재활용 가능하고,
channel_integrations
도 SNS 업로드에 그대로 씁니다.
이미지도 보면 Replicate의 Flux 모델로 생성하셨는데, 프롬프트 구조는 완벽합니다. 스타일 설명, 샷 타입, 씬 내용, 조명까지 체계적으로 잡혀 있어요. 이걸 gpt-image-2로 교체하면 됩니다.
실질적으로 필요한 변경 세 가지
1.
jobs
테이블 추가 — 가장 중요합니다. 지금은 단계별 실행이 직렬로 이어지기 때문에 중간 실패 시 전체가 죽습니다.
jobs
테이블로 각 단계를 독립적으로 관리하면 실패한 단계만 재시도할 수 있습니다.
CREATE TABLE jobs (
id INT AUTO_INCREMENT PRIMARY KEY,
project_id INT NOT NULL,
step ENUM('blog','thumbnail','cardnews','script',
'audio','keyshots','zip') NOT NULL,
status ENUM('pending','running','done','failed') DEFAULT 'pending',
retry_count TINYINT DEFAULT 0,
result_path TEXT,
error_msg TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);2.
settings
에서 Replicate 제거, OpenAI 추가 —
replicate_api_key
는 빼고
openai_api_key
하나 추가하면 됩니다. ElevenLabs 키는 이미 칸이 있는데 값이 비어있네요.
3.
projects
에
content_type
추가 — 블로그용인지, 쇼츠용인지, 인스타용인지 구분하는 컬럼 하나만 있으면 같은 파이프라인을 다양하게 활용할 수 있습니다.




댓글 (0)
댓글 쓰기